Empirical Methods in Finance
Practicing 4
Plotting this relationship in a graph, you get:
library(ggplot2)
library(ggthemes)
ggplot(df) + geom_point( aes(x=x, y=y), color = "lightblue") +
geom_smooth(data = df, aes(x=x, y=y) , method = lm) +
theme_solarized() +
labs(title = paste("Beta is" , round(summary(lm(df$y ~ df$x))$coefficients[2,1], 3) ,
", Beta t-stat is" , round(summary(lm(df$y ~ df$x))$coefficients[2,3], 3) ,
", R2 is" , round(summary(lm(df$y ~ df$x))$r.squared , 3) ,
", Sample Size is" , nrow(df) ) ) 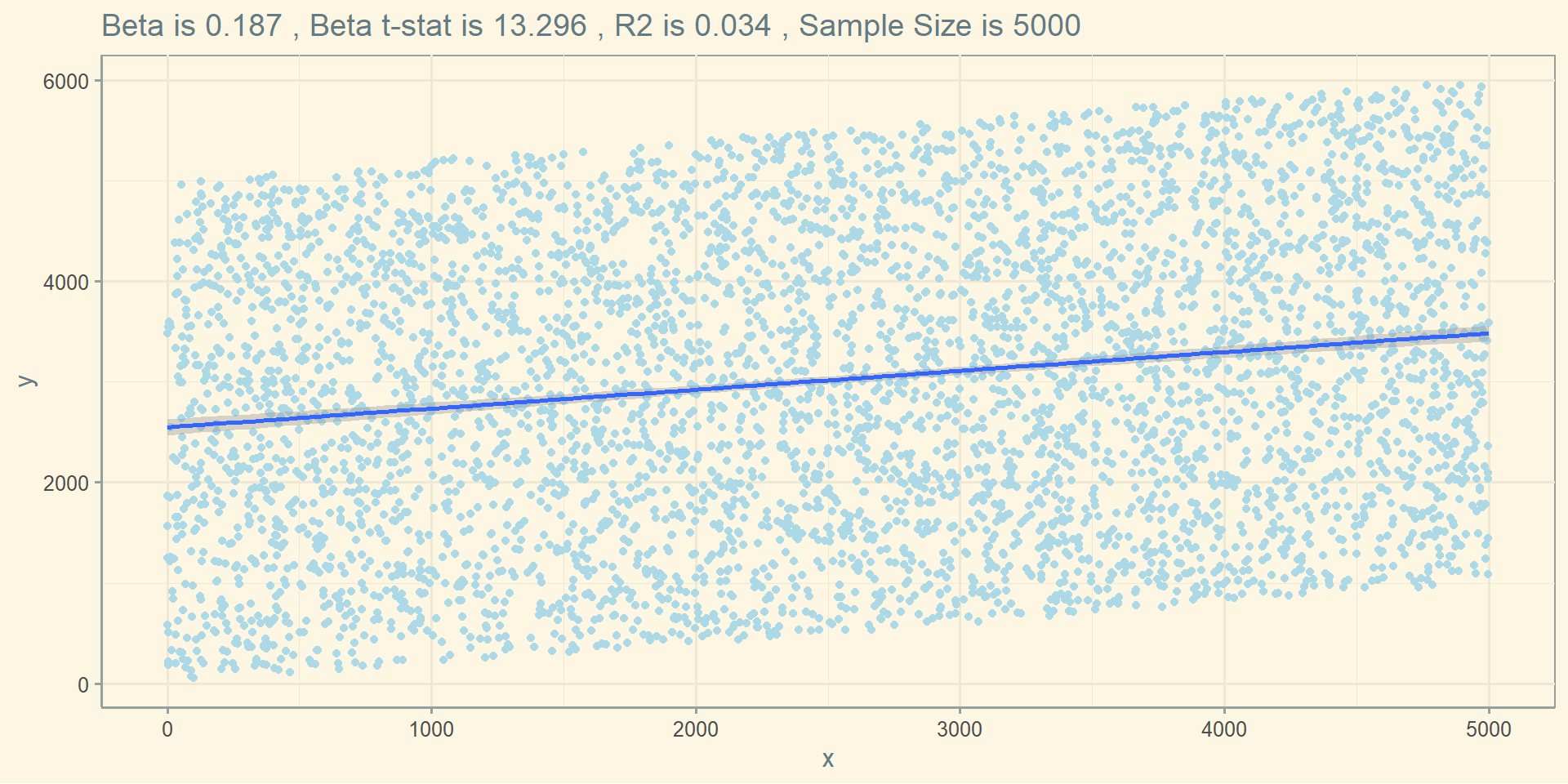
If you run a linear model using the sample you can observe, you might get this.
library(dplyr)
set.seed(1235)
random <- sample_n(df, sample)
reg <- lm(random$y ~ random$x)
sum <- summary(reg)
ggplot(df) + geom_point( aes(x=x, y=y), color = "grey") +
geom_point( data = random, aes(x=x, y=y) , color = "blue") +
geom_smooth(data = random, aes(x=x, y=y) , method = lm) +
theme_solarized() +
labs(title = paste("Beta is" , round(reg$coefficients["random$x"], 3) ,
", Beta t-stat is" , round(summary(reg)$coefficients[2 , 3] , 3) ,
", R2 is" , round(summary(reg)$r.squared , 3) ,
", Sample Size is" , nrow(random) ) ) 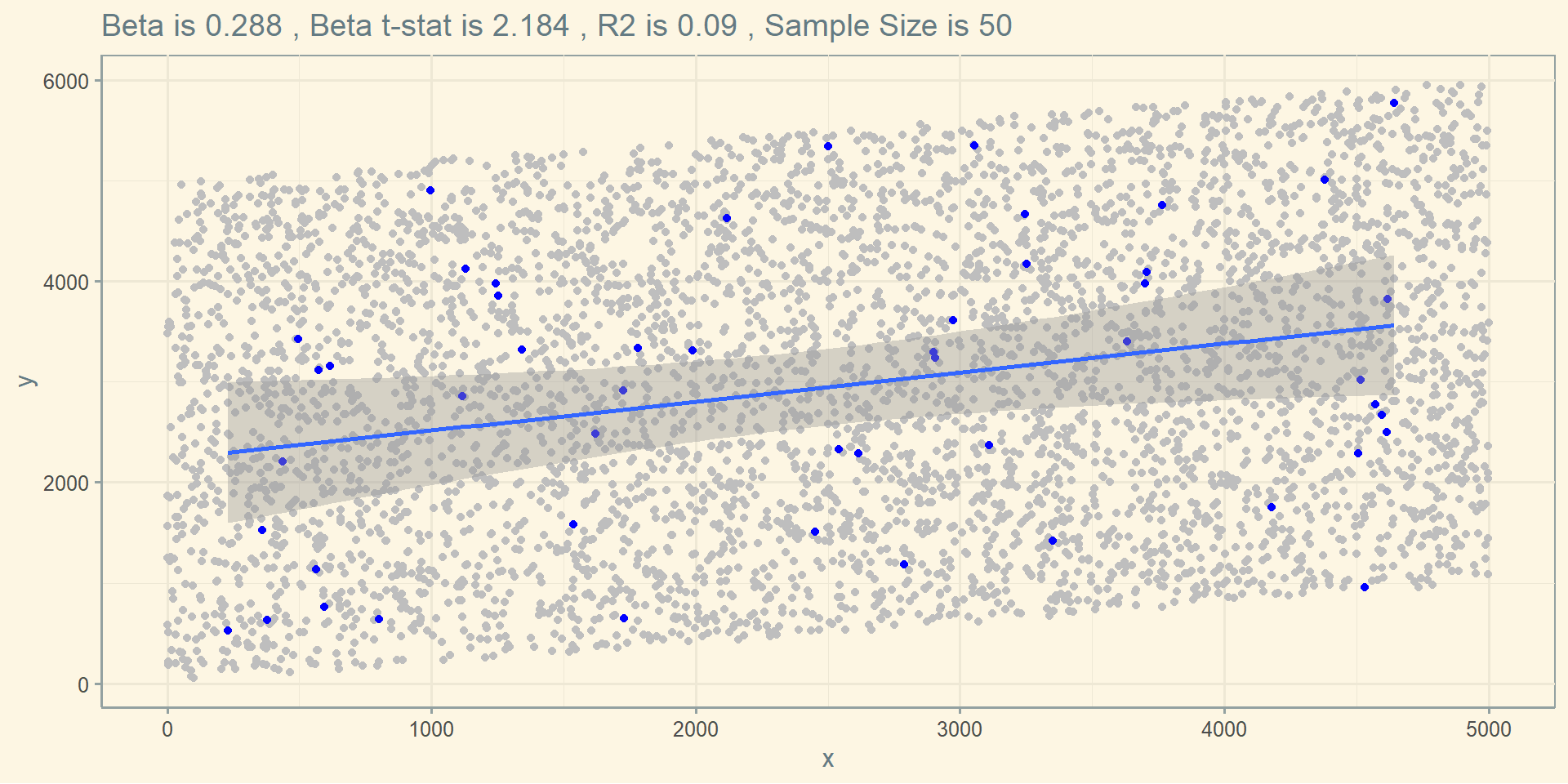
Or maybe this:
set.seed(1242)
random <- sample_n(df, sample)
reg <- lm(random$y ~ random$x)
sum <- summary(reg)
ggplot(df) + geom_point( aes(x=x, y=y), color = "grey") +
geom_point( data = random, aes(x=x, y=y) , color = "blue") +
geom_smooth(data = random, aes(x=x, y=y) , method = lm) +
theme_solarized() +
labs(title = paste("Beta is" , round(reg$coefficients["random$x"], 3) ,
", Beta t-stat is" , round(summary(reg)$coefficients[2 , 3] , 3) ,
", R2 is" , round(summary(reg)$r.squared , 3) ,
", Sample Size is" , nrow(random) ) ) 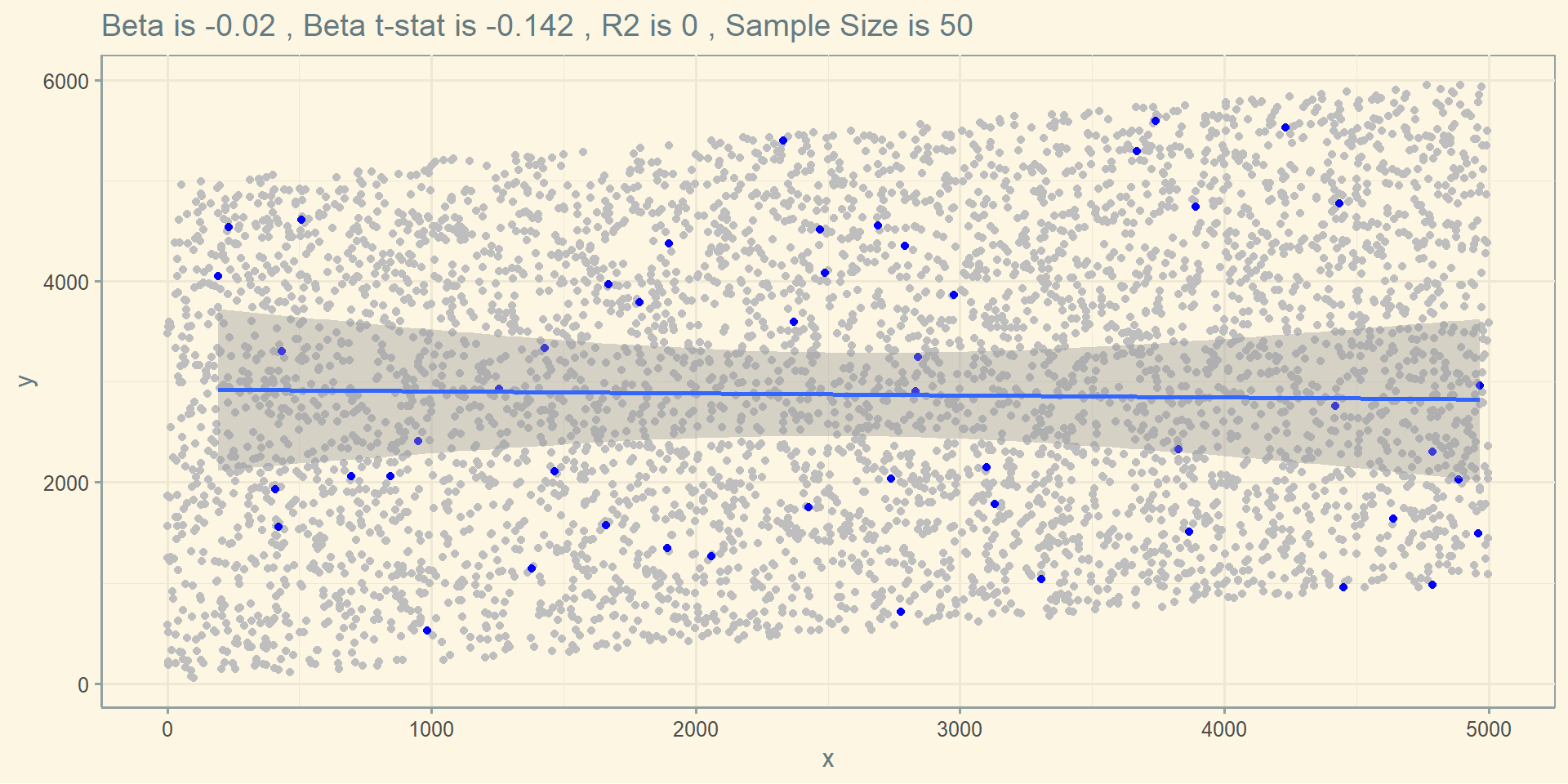
Or maybe this:
set.seed(1243)
random <- sample_n(df, sample)
reg <- lm(random$y ~ random$x)
sum <- summary(reg)
ggplot(df) + geom_point( aes(x=x, y=y), color = "grey") +
geom_point( data = random, aes(x=x, y=y) , color = "blue") +
geom_smooth(data = random, aes(x=x, y=y) , method = lm) +
theme_solarized() +
labs(title = paste("Beta is" , round(reg$coefficients["random$x"], 3) ,
", Beta t-stat is" , round(summary(reg)$coefficients[2 , 3] , 3) ,
", R2 is" , round(summary(reg)$r.squared , 3) ,
", Sample Size is" , nrow(random) ) ) 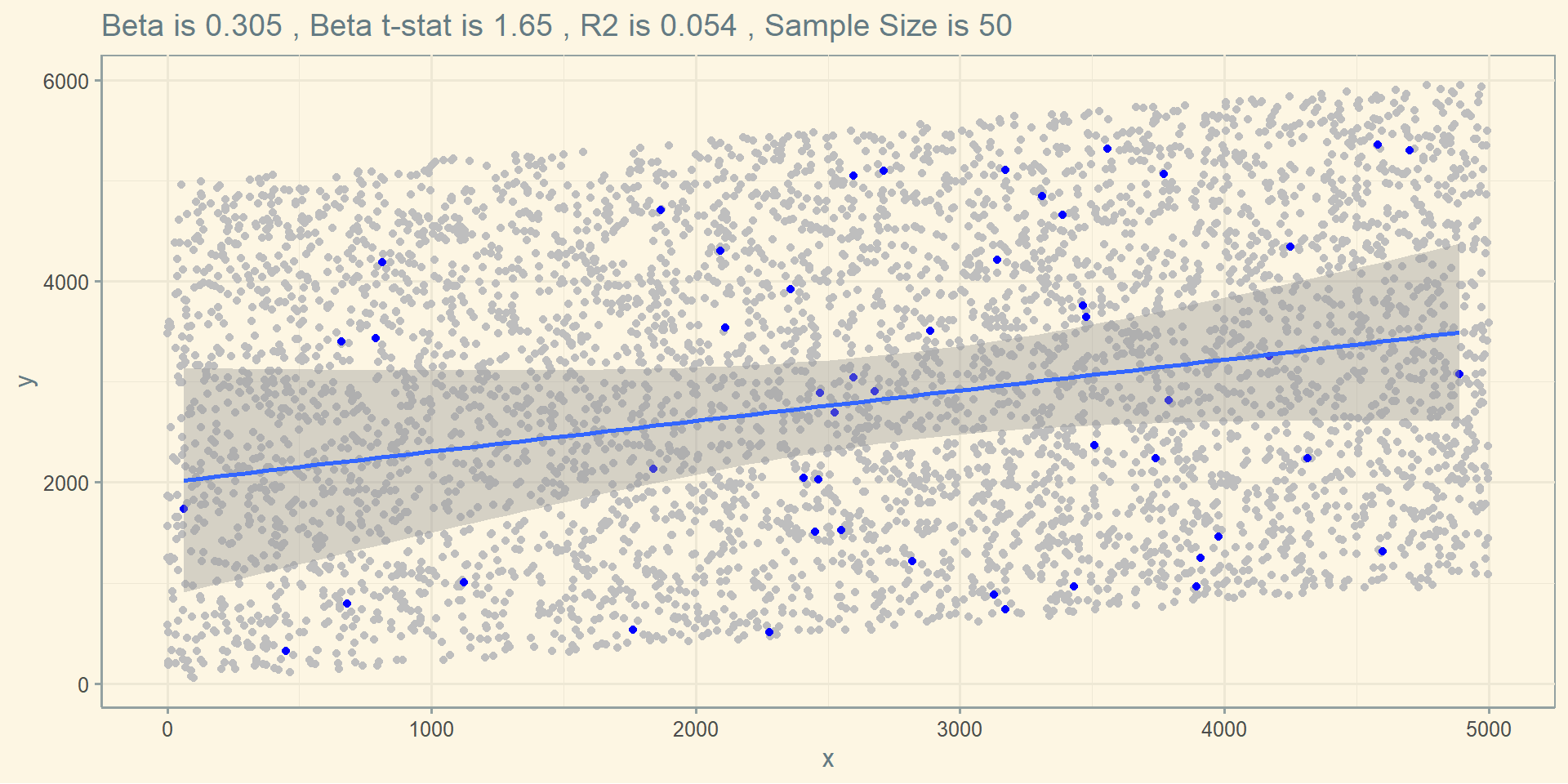
🙋♂️ Any Questions?
Thank You!

