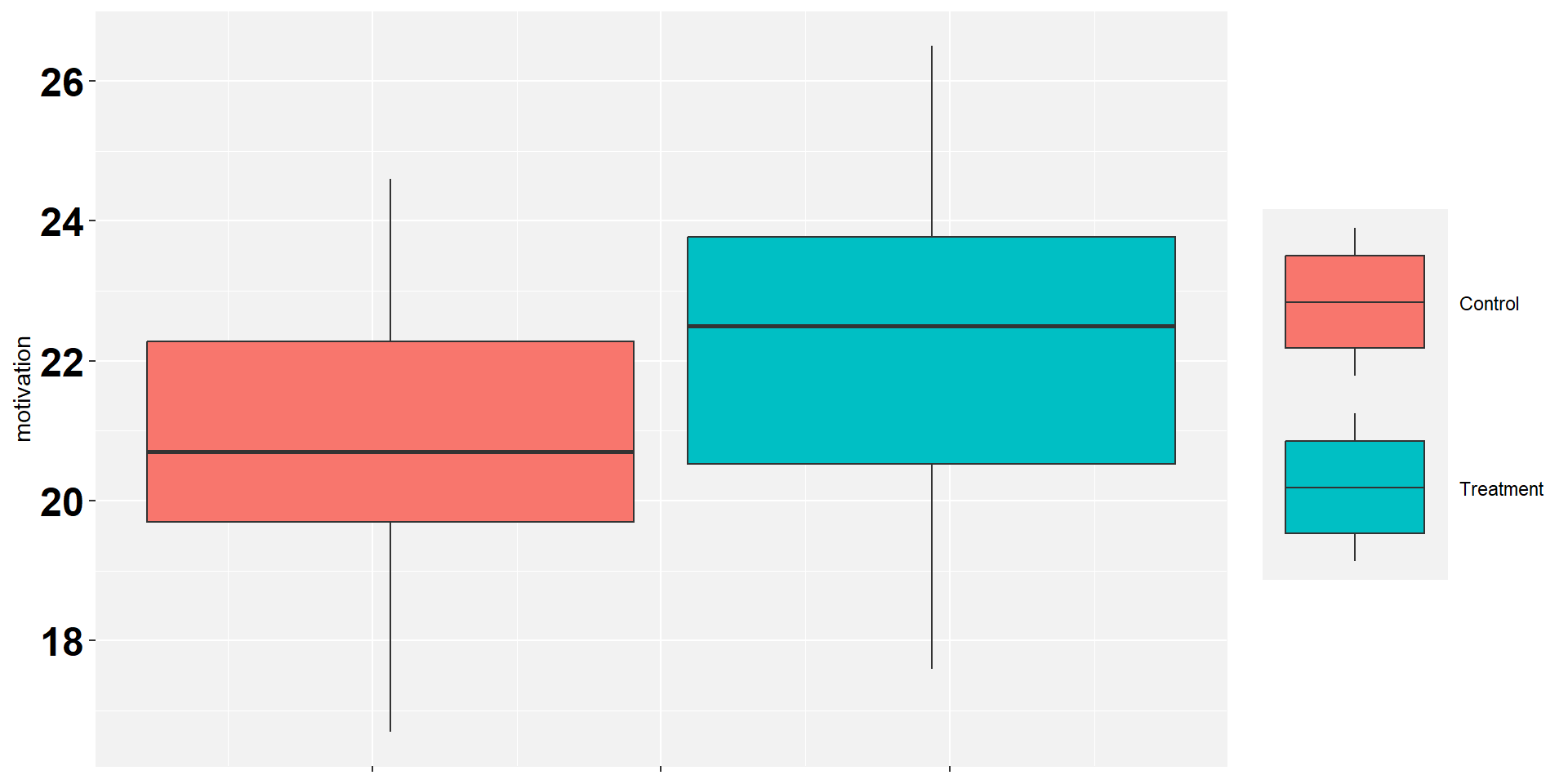
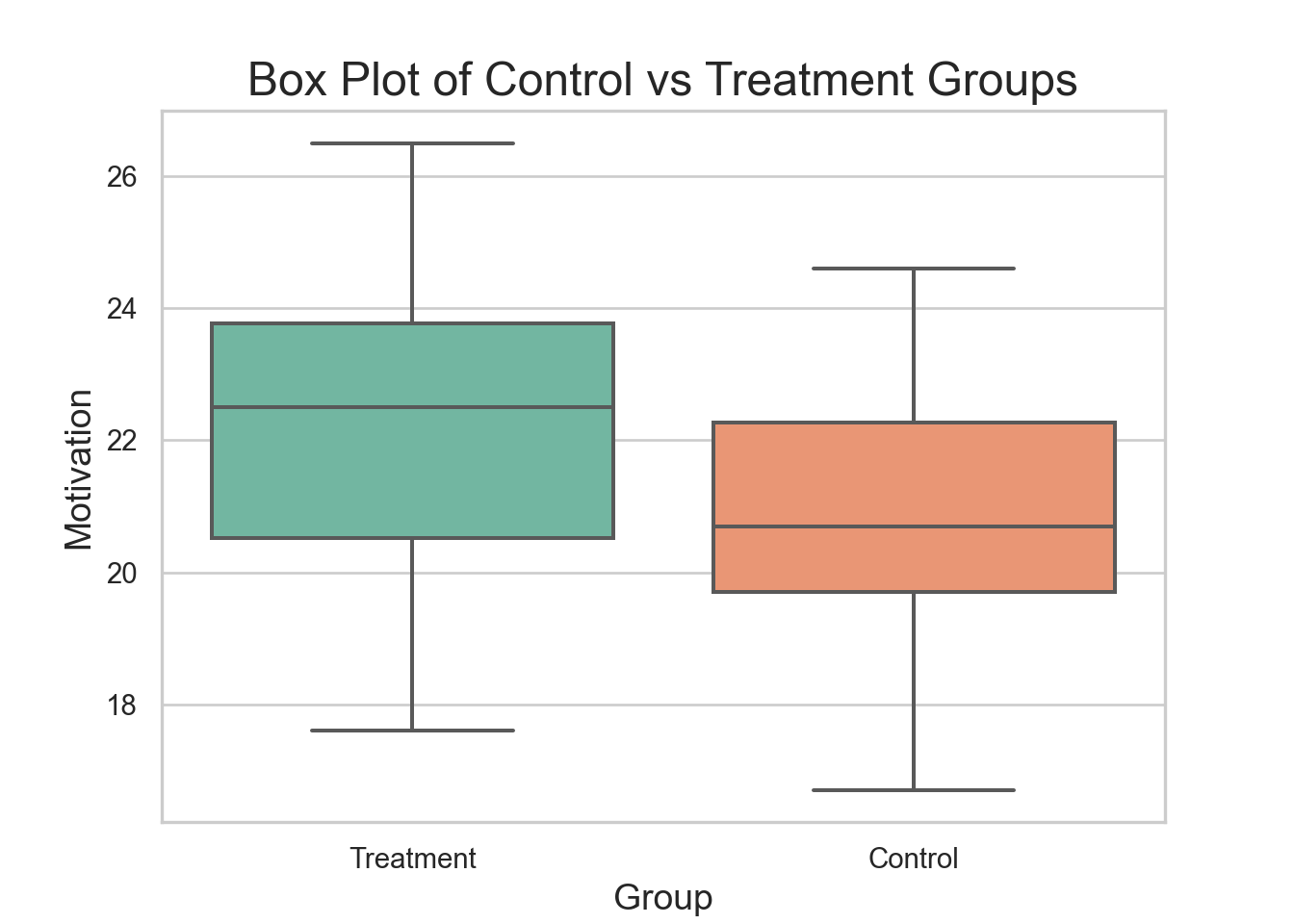
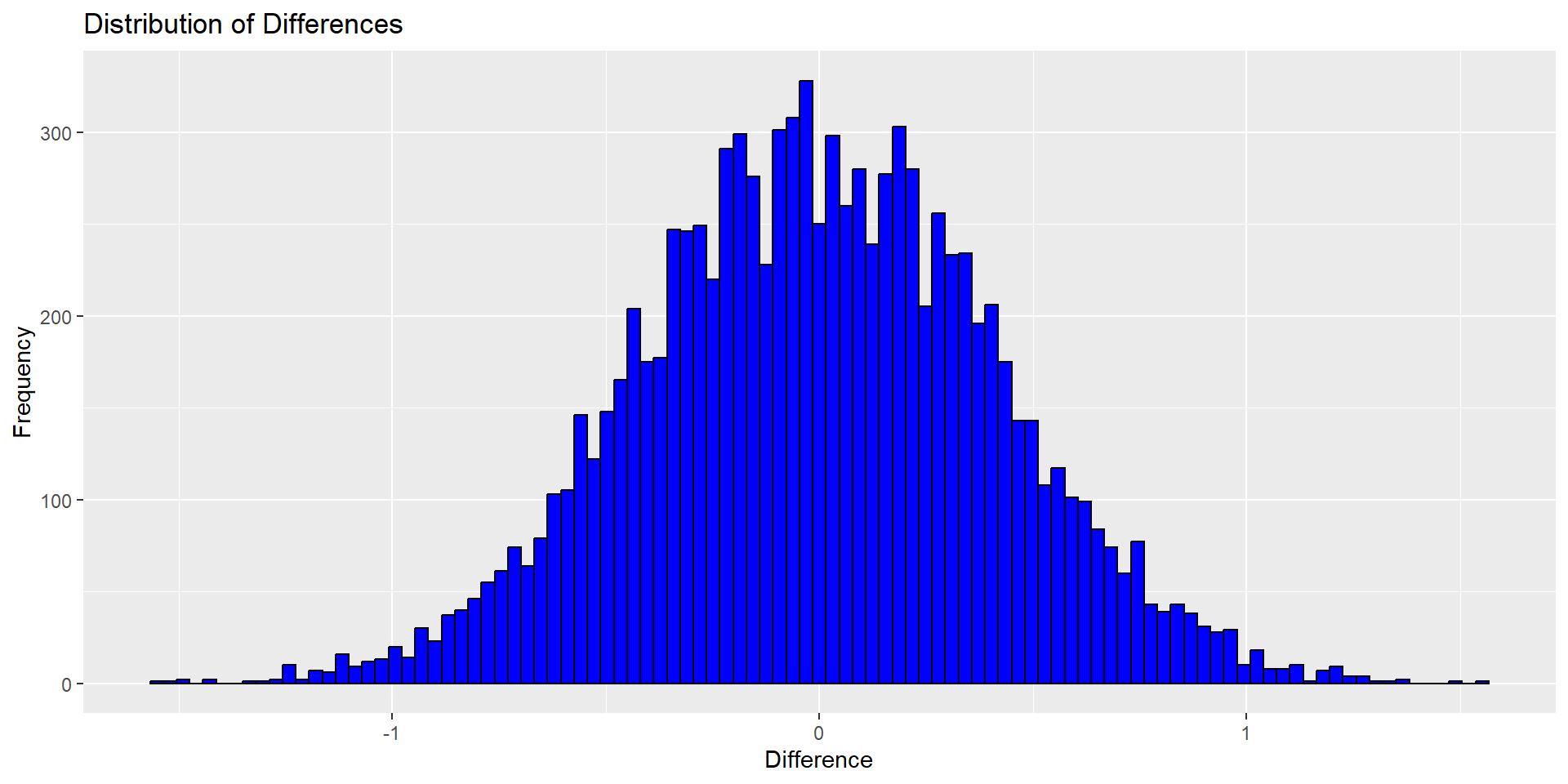
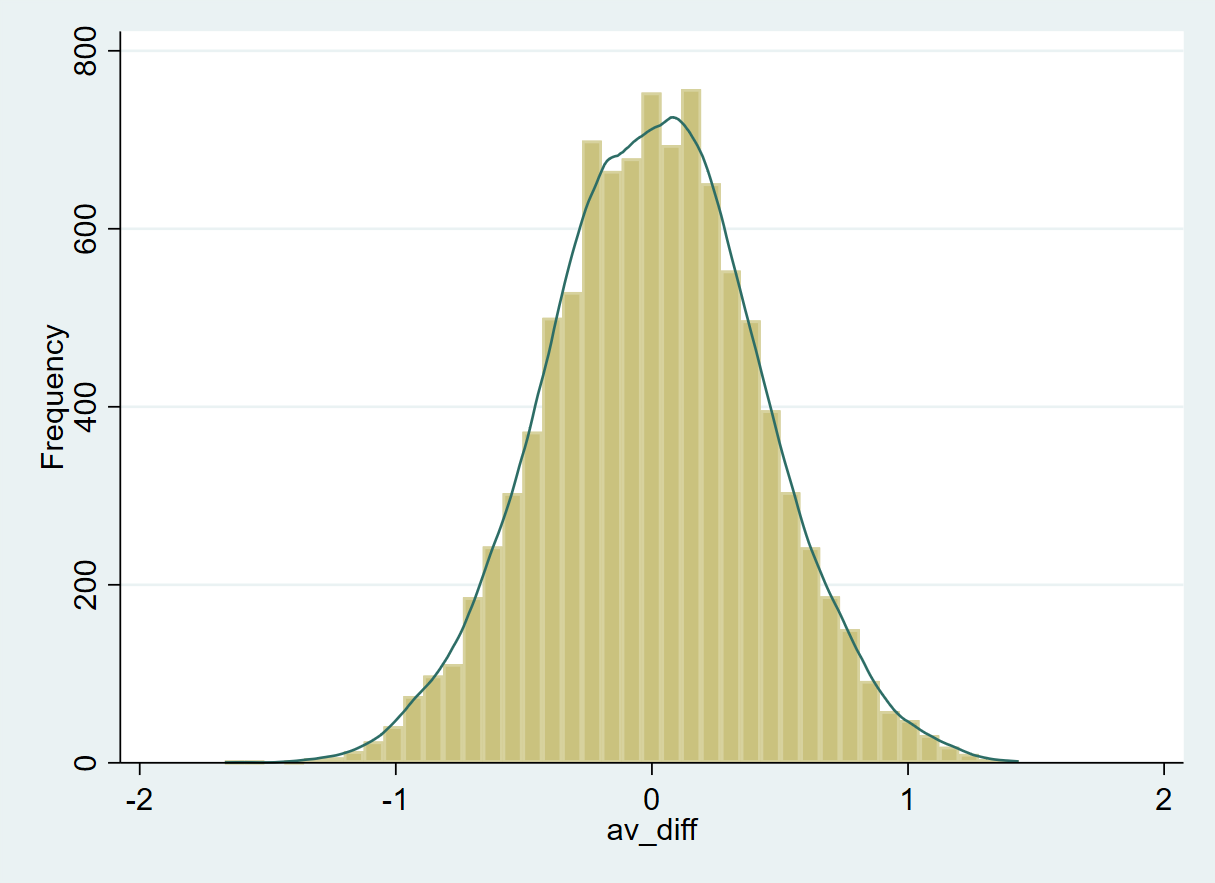
R
# Create the data frame
data <- data.frame(
id = 1:9,
earnings = c(110000, 100000, 110000, 60000, 30000, 115000, 75000, 90000, 60000),
school = c("private", "private", "public", "private", "public", "private", "private", "public", "public"),
private = c(1, 1, 0, 1, 0, 1, 1, 0, 0),
group = c(1, 1, 1, 2, 2, 3, 3, 4, 4)
)
print(data) id earnings school private group
1 1 110000 private 1 1
2 2 100000 private 1 1
3 3 110000 public 0 1
4 4 60000 private 1 2
5 5 30000 public 0 2
6 6 115000 private 1 3
7 7 75000 private 1 3
8 8 90000 public 0 4
9 9 60000 public 0 4