R
Part 2
Sometimes, there is causality even when we do not observe correlation.
The sailor is adjusting the rudder on a windy day to align the boat with the wind, but the boat is not changing direction. (Source: The Mixtape)
Note
In this example, the sailor is endogenously adjusting the course to balance the unobserved wind.

Imagine that you want to investigate the effect of Governance on Q
\(𝑸_{i} = α + 𝜷_{i} × Gov + Controls + error\)
All the issues in the next slides will make it not possible to infer that changing Gov will CAUSE a change in Q
That is, cannot infer causality

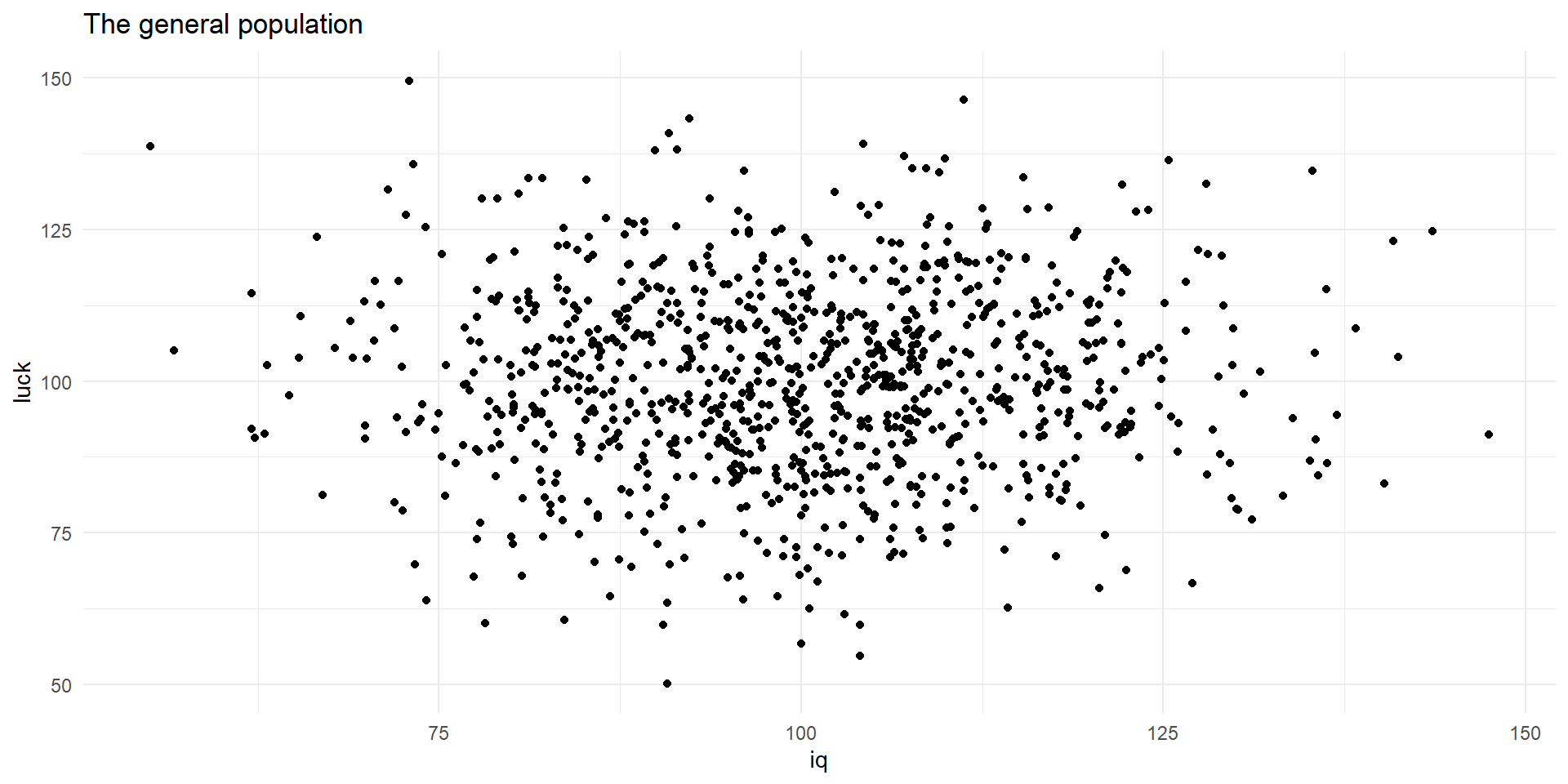
A representation of the population
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(100)
luck = np.random.normal(100, 15, 1000)
iq = np.random.normal(100, 15, 1000)
pop = pd.DataFrame({'luck': luck, 'iq': iq})
sns.set(style="whitegrid")
plt.figure(figsize=(8, 6))
plt.scatter(pop['iq'], pop['luck'])
plt.title("The general population")
plt.xlabel("IQ")
plt.ylabel("Luck")
plt.show()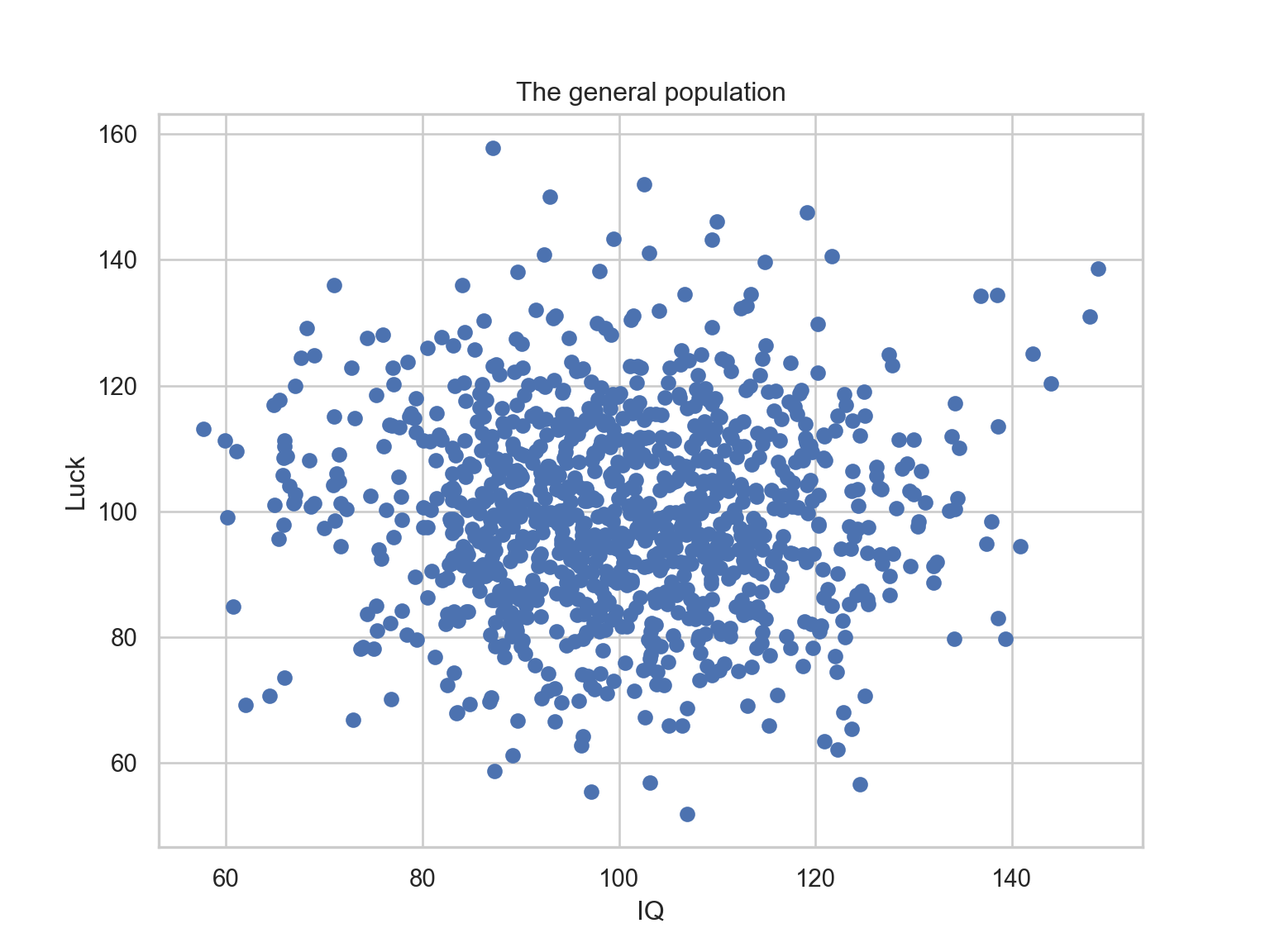
Important
Analyzing only successful people will suggest a negative correlation between luck and IQ.
library(data.table)
library(ggplot2)
set.seed(100)
luck <- rnorm(1000, 100, 15)
iq <- rnorm(1000, 100, 15)
pop <- data.frame(luck, iq)
pop$comb <- pop$luck + pop$iq
successfull <- pop[pop$comb > 240, ]
ggplot() +
geom_point(data = pop, aes(x = iq, y = luck)) +
geom_point(data = successfull, aes(x = iq, y = luck), color = "red") +
labs(title = "The general population & successful subpopulation") +
theme_minimal()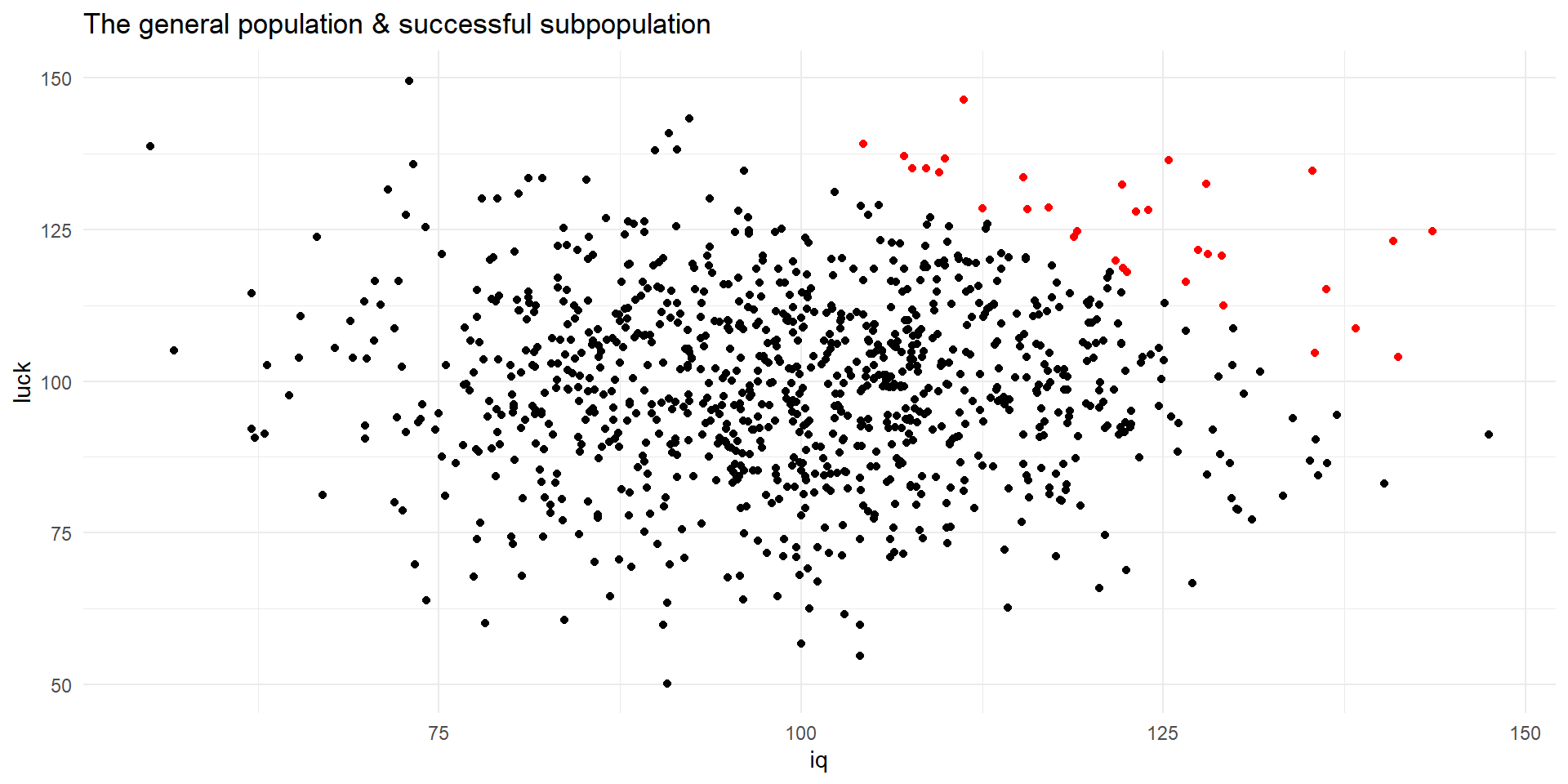
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(100)
luck = np.random.normal(100, 15, 1000)
iq = np.random.normal(100, 15, 1000)
pop = pd.DataFrame({'luck': luck, 'iq': iq})
pop['comb'] = pop['luck'] + pop['iq']
successful = pop[pop['comb'] > 240]
sns.set(style="whitegrid") # Minimalistic theme similar to theme_minimal in ggplot2
plt.figure(figsize=(8, 6))
plt.scatter(pop['iq'], pop['luck'], label="General Population", alpha=0.5)
plt.scatter(successful['iq'], successful['luck'], color='red', label="Successful Subpopulation", alpha=0.7)
plt.title("The general population & successful subpopulation")
plt.xlabel("IQ")
plt.ylabel("Luck")
plt.legend()
plt.show()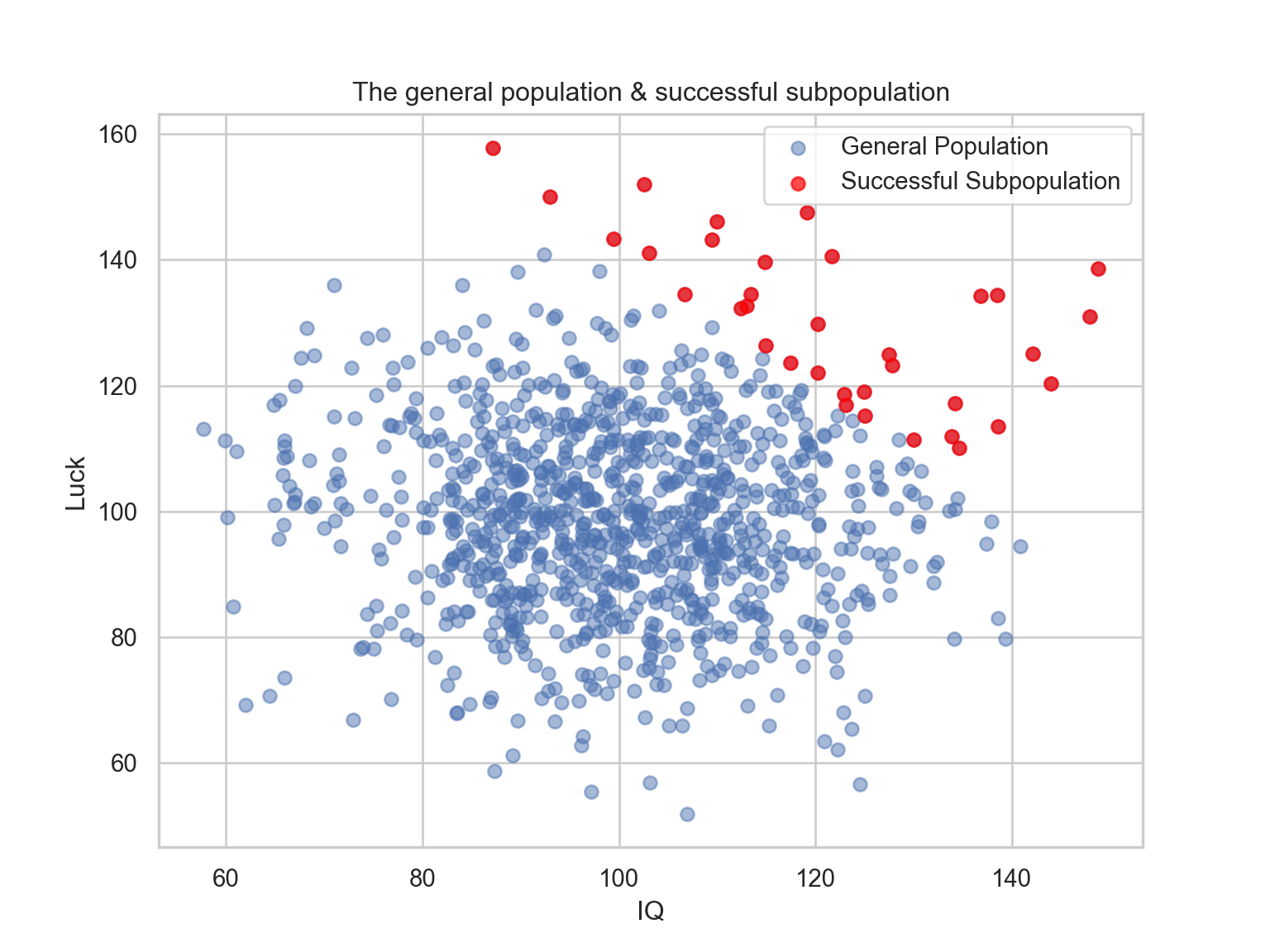
set seed 100
set obs 1000
gen luck = rnormal(100, 15)
gen iq = rnormal(100, 15)
gen comb = luck + iq
gen successful = comb > 240
twoway (scatter luck iq if successful == 0) (scatter luck iq if successful == 1, mcolor(red)) , title("The general population & successful subpopulation")
quietly graph export figs/collider2.svg, replaceNumber of observations (_N) was 0, now 1,000.
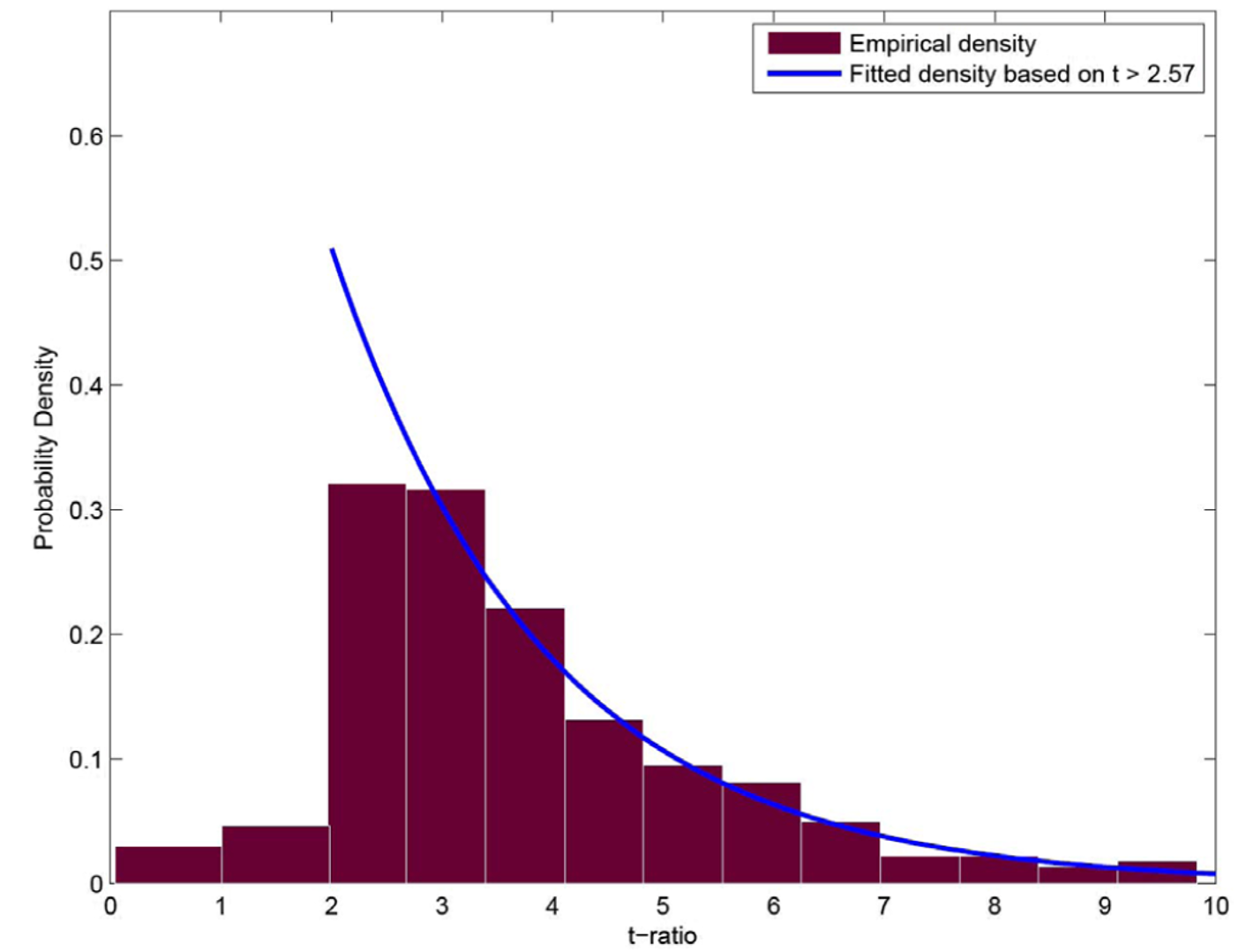
P-Hacking
Artigo original aqui.
Publication bias
Artigo original aqui.
Crise de replicação
Artigo original aqui.