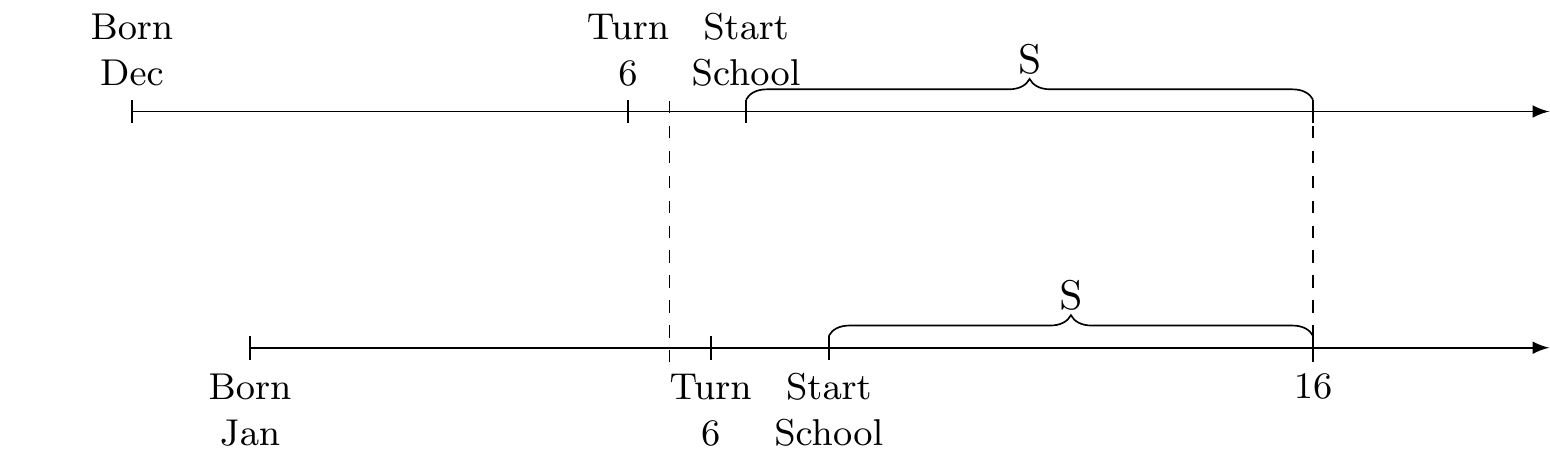
Weak Instruments
I did not demonstrate here, but we can say that (see pp; 517-18 Wooldridge):
- though IV is consistent when \(z\) and \(u\) are uncorrelated and \(z\) and \(x\) have any positive or negative correlation, IV estimates can have large standard errors, especially if \(z\) and \(x\) are only weakly correlated.
This gives rise to the week instruments problem.
We can write the probability limit of the IV estimator:
\[plim \hat{\beta_{iv}} = \beta_1 + \frac{Corr(z,\mu)}{Corr(z,x)} \times \frac{\sigma_{\mu}}{\sigma_x}\]
It shows that, even if \(Corr(z,\mu)\) is small, the inconsistency in the IV estimator can be very large if \(Corr(z,x)\) is also small.