Ethics & Open Data (ANPCONT)
2022-12-03

My opinions are my own, not those of the Institution I work for.
What is NOT a problem anymore
- Your files CAN be cited

Very easy to create PlumX metrics for your files.
What is NOT a problem anymore
- General Awareness and Incentives Source.

What is NOT a problem anymore
- General Awareness and Incentives Source.

What is NOT a problem anymore
- General Awareness and Incentives Source.

What is NOT a problem anymore
- General Awareness and Incentives Source.

What is NOT a problem anymore
- General Awareness and Incentives Source.

What ARE the problems (in my opinion)
- Scholars’ lack of organization Source
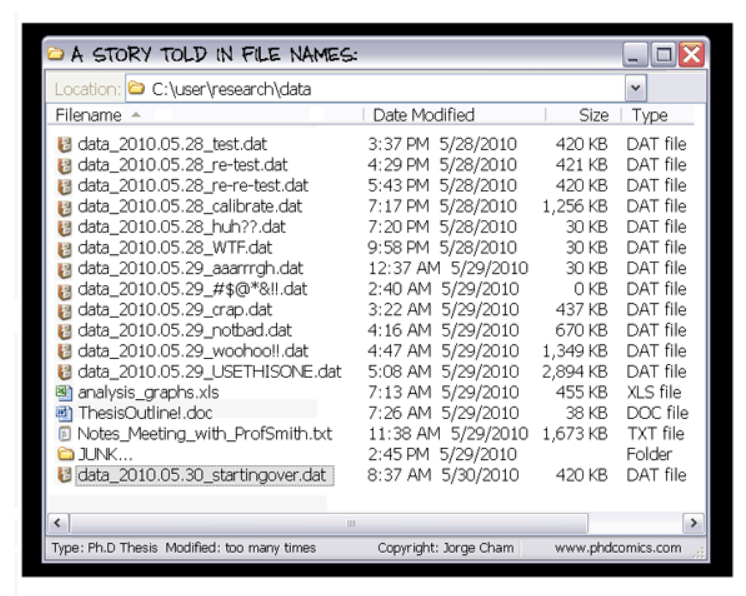
What ARE the problems (in my opinion)
- Scholars’ lack of organization
- Never change the original excel (you will never remember the changes you have made). Instead, make data changes inside your code (i.e., Stata do file).
- Start using some solution for version control. For example, Github (It is free!!).
What ARE the problems (in my opinion)
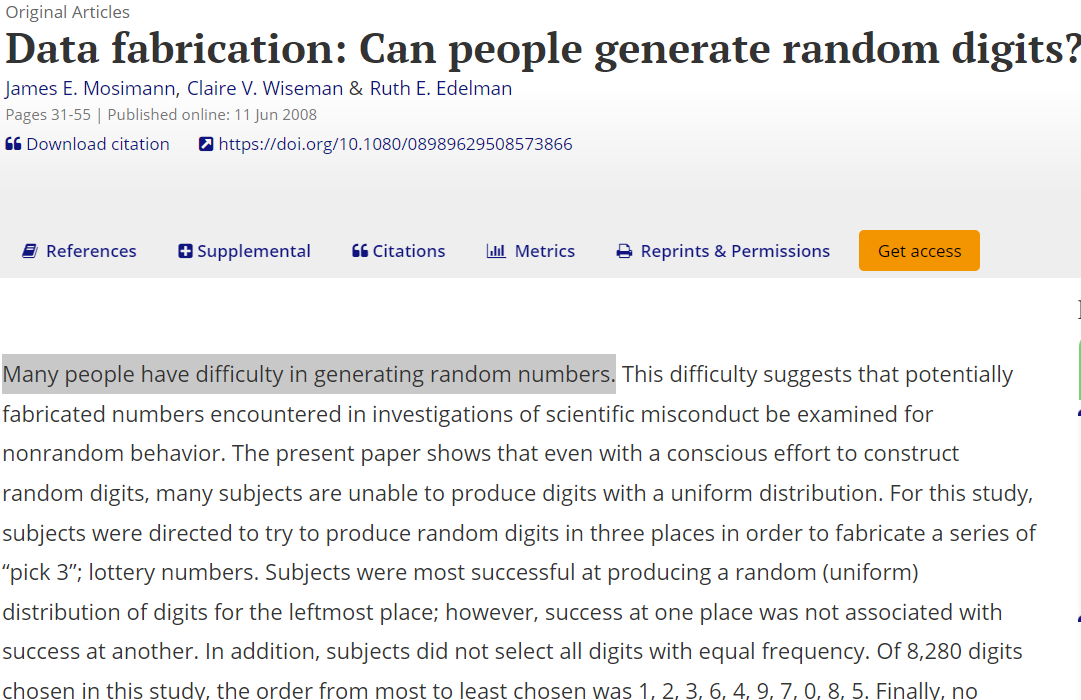
Before you have the idea to fabricate data, beware that… Source
What ARE the problems (in my opinion)
- Journals are still learning how to create internal protocols to share data.
“Code” is just a couple of files. You should share it.
- But sharing code only goes so far. Experienced researchers can evaluate the quality of your code and use it as a subjective proxy for the quality of your work.
- If you write good codes, you should share them. If you write bad codes, start writing good ones (simple, clear, etc.)
- Obviously, the journal needs to be able to publish your code.
THANK YOU!

